Viva La Vida
RobustNeRF:
Ignoring Distractors with Robust Losses
数据集:拍摄 + 合成
拍摄数据集(自然场景)
拍摄场景:公寓场景、机器人实验室
数据集采集图片数量如下表
| 名称 | #extra | #clutter | #clean | total | paired? | resolution | setting | distractor |
|---|---|---|---|---|---|---|---|---|
| Android | 19 | 122 | 122 | 263 | clean&clut Yes extra No |
4032×3024 | Apartment | 三个小型木制机器人 |
| Statue | 19 | 142 | 255 | 416 | No | 4032×3024 | Apartment | 飘动的气球 |
| Crab (2) | 194 | 109 | 109 | 412 | clean&clut Yes extra No |
3456×3456 | Robotics Lab | 小型玩具(刀叉、食物玩具、瓶子等) |
| BabyYoda | 202 | 109 | 109 | 420 | clean&clut Yes extra No |
3456×3456 | Robotics Lab | 小型玩具(刀叉、食物玩具、瓶子等) |
1.公寓场景(Statue & Android)
- 拍摄公寓里的两个桌面场景
- 聚焦于桌面上的物体
- 从物体周围半球方向的不同视角拍摄照片
- 桌子上的一部分物体从一张照片移动到另一张照片
- 没有明确的时间顺序
- 无恒定照明
包括 无干扰物(0clean)、带有干扰物(2clutter)的图片(相机位姿配对的图片) 示例如下:


还包括额外的(1extra)图片,无干扰物,没有配对的相机位姿
- 拍摄设备:iPhone 12 mini
- 软件:ProCamera v15 (控制相机曝光设置)
- 快门速度(曝光时间):1/60 s
- shutter speed 指的是 曝光时间,即快门打开的时间长度,以秒或分数秒表示。例如,1/60 表示快门每次打开的时间为 1/60 秒。较长的曝光时间会让更多光线进入传感器,但可能导致移动物体模糊,而较短的曝光时间则适合抓拍运动场景,但在低光环境下可能导致画面较暗。
- 曝光补偿:0.0
- exposure bias(曝光补偿)是指在自动曝光模式下人为调整相机计算出的曝光值,以使拍摄结果更亮或更暗。+0.0 的曝光补偿意味着不对自动曝光值进行任何调整。如果增加曝光补偿(如 +1),图像会比相机自动计算的亮;而减少曝光补偿(如 -1),图像则会变暗。
- ISO速度(感光度):200(Android) 80(Statue)
- 较低的 ISO 值有助于减少噪点,但可能需要更多的光。
- 镜头:iPhone 标准广角镜头
- 光圈大小(光圈值):F = f/1.6
- F是一个比值,没有单位,f是焦距大小,1.6(mm)指的是通光口径(光圈直径),f 值越小且光圈越大,F越小,则进光量越多,景深越浅,适合低光环境
- 将相机固定在三脚架上保持稳定,减少滚动快门(rolling shutter)效应对图像的影响
- 滚动快门效应是因为大多数相机的图像传感器并不是在瞬间同时读取整个画面,而是逐行逐行地读取图像。对于移动物体或抖动的相机,这种逐行扫描的方式会导致图像中的物体出现变形。例如,快速移动的物体会被拍成倾斜的样子,或者在拍摄时相机轻微抖动,画面可能会变得波浪状。
Android场景
描绘了两个 Android 机器人站在一个棋盘游戏盒上,棋盘游戏盒放在一张铺有图案桌布的桌子上。 在每张包含干扰物的照片中,以不同的方式将三个小型木制机器人放在桌子上,以充当干扰物。
Statue场景
描绘了木制餐桌上一个精致的装饰盒顶部的一个小雕像。为了模拟某种持久的干扰物,将一个气球漂浮在桌子上,在整个拍摄过程中,它会随着每张照片自然地稍微改变位置。
与 Android 场景不同的是,在每帧中,干扰物都会移动到全新的姿势,而气球通常会在多张照片中占据相同的空间体积。装饰盒和厨房桌子都展现出细粒度的纹理细节。
- 使用COLMAP的SIMPLE_RADIAL相机模型进行SfM稀疏重建
遇到的一些挑战
在公寓场景中,拍摄的照片背景中每个物体都会出现部分曝光过度或者曝光不足的情况,而且只出现在部分照片中。(较难捕获受控的静态场景)
失败案例:
- Android数据集:桌布的褶皱重建失败,背景的椅子缺乏重建细节(这里论文中说明的原因是在拍摄过程中桌布有移动,少量的背景捕获不足以进行高保真重建)
- Statue数据集:拍摄的图片存在过度曝光和颜色较准问题,因此渲染图像和GT在外观颜色上有一些差别

2.机器人实验室场景(Crab & BabyYoda)
- 使用机械臂将相机随机放在桌子上方1/4半球范围内
- 封闭的隔间,室内有恒定的照明
- 桌上放置一些小型玩具,其中一部分粘在桌子上防止移动
- 拍摄过程中,干扰玩具被移除和/或引入新的干扰玩具
- 拍摄相机和镜头:Blackfly S GigE 相机、TECHSPEC 8.5mm C 系列定焦镜头
- 原始图片分辨率:5472×3648,通过中心裁剪将其裁剪为3456×3456,可以减少因镜头引起的图像边缘失真
- 位深:以12位RAW格式采集,12位深度保留了丰富的色彩和亮度细节(我查看图片的详细信息,位深度为24,即3个通道每个通道8位,可能是色彩校准步骤将RAW格式转换为了标准的RGB格式),原始照片会根据参考调色板自动进行颜色较准
- 光圈:f/8
- 曝光时间:650 ms
Crab场景
目前为止发现extra图片拍摄都是接近中心物体的,可能只包含物体的一部分
BabyYoda场景
以上两个场景extra图片无干扰物,用于评估。因为是手动放置干扰玩具,整个采集过程会比较耗时(一个场景一般需要几个小时)
合成数据集(合成场景)
生成了3个类似于D²NeRF合成场景的Kubric场景,有简单、中等和困难三个难度级别,通过控制离群值的占用比例用于消融实验(项目官方页面提供的数据集没有合成场景)
- 每个数据集包含200张用于训练的带有干扰物的图像和100张用于评估的干净图像
- 所有三个场景中,静态物体包括沙发、灯和书架
- 简单的场景仅包含1个小的干扰对象(一个小型背包)
- 中等场景有3个干扰物(一个中型背包、一把椅子和一辆汽车),这些干扰物的尺寸较大,因此离群值占用率是简单场景的离群值占用率的 4 倍
- 困难场景有6个大型干扰物(一个大型背包、一把椅子和四辆车),平均比简单场景多占用 10 倍的像素,覆盖每张图像的大概一半
NeRF on-the-go:
Exploiting Uncertainty for Distractor-free NeRFs in the Wild
- 目标(解决的问题):训练静态场景的NeRF,有效去除在野外随意捕获的(图像序列/视频)场景中所有动态干扰(汽车、电车、行人等)
- 方法:利用预测的不确定性图(uncertainty maps)去除干扰因素
与其他工作的比较:
- D²NeRF可以分解视频输入的动静态场景,但是对于稀疏图像输入表现不佳
- RobustNeRF将干扰因素建模为异常值,但是其场景较简单,在复杂野外场景中性能不佳,在没有任何干扰因素的情况下也表现不佳
能否不管干扰物比例如何,都能用NeRF重建出野外随意捕获的场景?
本文
- 利用DINOv2特征在特征提取中的鲁棒性和时空一致性,从中使用一个小型MLP预测每个样本像素的不确定性
- 利用结构相似性损失改进不确定性优化,增强前景干扰物和静态背景的区别
- 使用解耦训练策略将估计的不确定性纳入NeRF的图像重建目标中,显著增强了干扰消除的效果
数据集
Method
-
利用每像素DINOv2特征进行不确定性预测
- 首先为每个输入图像提取DINOv2特征(该特征可以保持跨视图的时空一致性)
- 然后将这些特征作为小型MLP的输入来预测每个像素的不确定性值,基于小批量内特征向量的余弦相似性选择一个batch里的邻居集合$N(r)$,射线r的精确不确定性计算为$N(r)$的平均值
- 引入正则化项$L_{reg}$(惩罚$N(r)$内的不确定性方差),平滑跨图像射线相似特征的不确定性预测的突变,增强不确定性预测的一致性(让相似光线的不确定性预测趋向一致)
$$L_{reg}(r)=\frac{1}{\lvert N(r)\rvert}\sum_{r'\in N(r)}(\bar\beta(r)-\beta(r'))^2$$
-
学习不确定性消除干扰物
- 假设动态干扰相关像素有高不确定性,静态区域像素有低不确定性
- 通过推导发现不确定性预测和 渲染像素颜色与真值之间的误差 成正比,这就导致当动态干扰因素与背景颜色相似时,不确定性预测会变低。提出一个基于SSIM的Loss用于增强不确定性学习
- 基于亮度、对比度、结构相似度 $$L_{SSIM}=(1−L(P, \hat{P}))·(1−C(P, \hat{P}))·(1−S(P, \hat{P}))$$ 其中$P$和$\hat{P}$分别是从输入图像和渲染图像中采样的patch $$L_{uncer}(r)=\frac{L_{SSIM}}{2\beta(r)^2}+\lambda_1 log\beta(r)$$
-
用于不确定性预测和NeRF的解耦优化方案
- 用$L_{nerf}(r)$训练NeRF
$$L_{nerf}(r)=\frac{\lVert C(r)-\hat{C}(r) \rVert^2}{2β^2(r)}$$
- 总体目标是综合所有损失
$$L=\lambda L_{nerf}(r)+\lambda_3 L_{uncer}(r)+\lambda_4 L_{reg}(r)$$
-
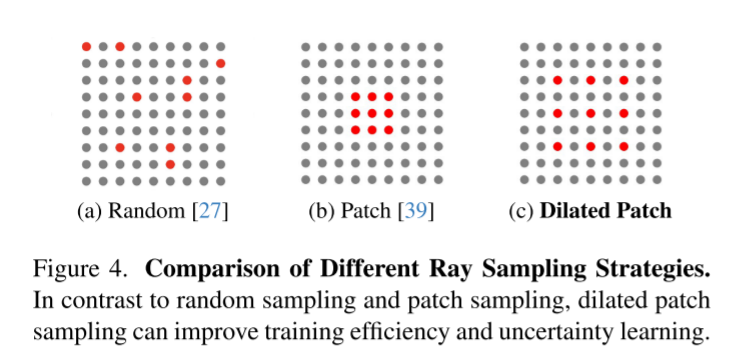
为什么采样方法在无干扰NeRF训练中很重要?——扩张patch采样
- 扩大patch可以增加每次训练迭代中可用的上下文信息量